先做个广告:如需代注册帐号或代充值Chatgpt Plus会员,请添加站长客服微信:pingzi7749
近日,OpenAI 发布新模型 o1 。
“对于复杂的推理任务来说,这是一个重大进步,代表了人工智能能力的新水平。鉴于此,我们将计数器重置为1,并将该系列命名为“OpenAI o1”。
OpenAI在其官方博客简述了o1背后的核心技术提升:“通过强化学习,o1 学会了精炼其思维链并优化所用的策略。它学会了识别并纠正错误,将复杂的步骤分解为更简单的部分,并在当前方法无效时尝试不同的途径。这一过程显著提升了模型的推理能力。”
o1的三个主要新能力:内化了思维链(COT)、能纠错、能尝试不同的途径。这些基本上与近几日业界讨论甚多的SelfPlay-RL(自我对弈型强化学习)的基本能力很符合。
强化学习与 self-play :让 AI 用随机的路径尝试新的任务,如果效果超预期,那就更新神经网络的权重,使得 AI 记住多使用这个成功的事件,再开始下一次的尝试。
华裔数学家陶哲轩向o1模型提出一个措辞模糊的数学问题,发现它竟然能成功识别出克莱姆定理。
这种感觉,就像给一个平庸无奇但又有点小能力的研究生提供建议。
大佬Maxim Lott,给o1、Claude-3 Opus、Gemini、GPT-4、Grok-2、Llama-3.1等进行了智商测试,结果表明,o1稳居第一名。紧随其后的,就是Claude-3 Opus和Bing Copilot,分别取得了第二名和第三名。
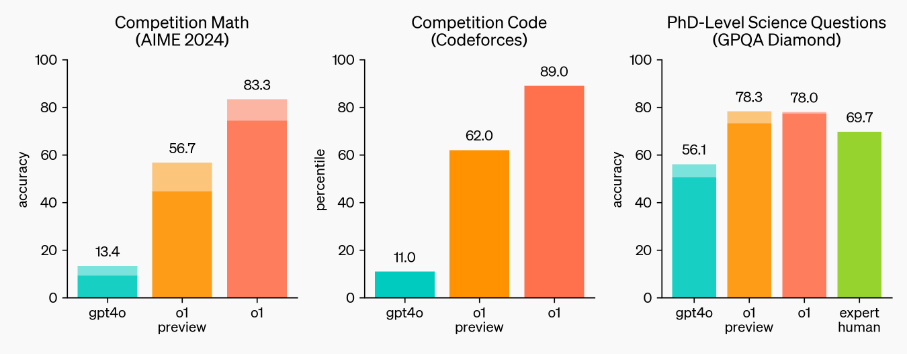
o1在最新门萨智商测试中,IQ水平竟超过了120分,把其他模型甩出好几条街。OpenAI的研究主管兼现任的IOI美国队教练Mark Chen称o1达到了「接近大师级的表现」。
大模型进化的瓶颈与OpenAI的解决方案
大模型Large Language Mode进化遇到瓶颈:数据瓶颈——数据不够用了;以及算力瓶颈——3.2万张卡已是目前的天花板。
强化学习的思路本质是用 inference time 换 training time 以解决边际收益递减问题。我们之前算过一笔账,对于 GPT-4 或 Claude-3.5 这种水平的模型,如果要合成 1T 高质量推理数据,需要 6 亿美金。如果合成 10T 高质量推理数据,需要 60 亿美金,这个量级很高。但是,与预训练不同的是, inference 对单张卡的性能,以及集群规模的性能要求相对低一些。不一定非要用最顶尖的卡,或 3-10 万卡的集群。分布式的集群也可以用来做强化学习的 inference 。
OpenAI o1 引入了新的技术范式,焦点从预训练向推理和强化学习转变。 o1 的推出标志着 AI 能力提升的新开端,但主要局限于数学和编程领域。 API 使用成本显著上升,订阅用户无需额外付费,但 API 用户需“花重金”使用。 o1 的思维链能力提升了推理性能,但对于生成直觉性和无固定答案的问题,则效果有限。 o1 使用 PRM 来提高推理过程中问题拆解和纠正错误的能力。 OpenAI 的成本策略强调了对推理成本的重视,高达 60 美元/百万 token 是一大亮点。 名称“OpenAI o1”显示出抛弃先前 GPT 模型名称的倾向,意图突显对推理能力的新注重。
强化学习与 self-play :让 AI 用随机的路径尝试新的任务,如果效果超预期,那就更新神经网络的权重,使得 AI 记住多使用这个成功的事件,再开始下一次的尝试。
技术创新能否成果不可预期
创建 o1 的基本原理可以追溯到多年前。前谷歌员工、风险投资公司 S32 的首席执行官安迪·哈里森指出,谷歌在 2016 年使用了类似的技术来创建 AlphaGo,这是第一个击败围棋世界冠军的人工智能系统。AlphaGo 通过与自己对弈无数次进行训练,基本上是自我学习,直到达到超人类的能力。
对于o1,也有人认为是被设计得过度思考的AI。
“这很令人印象深刻,但我认为改进并不是很显著,”纽约大学研究人工智能模型的教授拉维德·施瓦茨·齐夫说。“在某些问题上表现更好,但并没有普遍的改进。”
本文链接:https://www.vipbxr.vip/GPT5_380.html
GPTs机器人GPTs机器人AI机器人GPT-4.5 TurboGPT4.5GPT4.5发布GPT4.5网址GPT4.5网页版GPT4.5入口





网友评论