先做个广告:如需代注册帐号或代充值Chatgpt Plus会员,请添加站长客服微信:pingzi7749
最近,OpenAI 推出了新旗舰模型 GPT-4o ,尽管大幅提升了大语言模型的能力。但,该公司已经在开发下一个旗舰模型 GPT-6。
在 GPT-4o 发布之前,很多人都期待 OpenAI 能推出备受关注的 GPT-5。为了降低预期,首席执行官 Sam Altman 在 X 平台上发布了一篇 "不是 GPT-5,也不是搜索引擎 "的帖子。
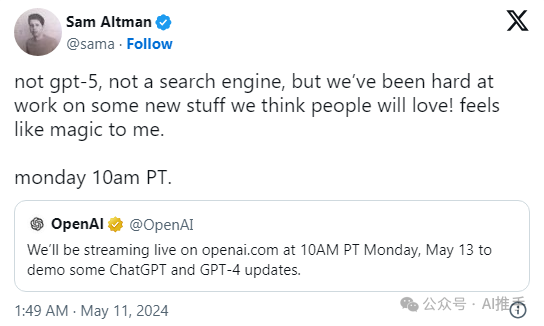
仅仅两周后,OpenAI 在一篇博客文章中公布了由 OpenAI 董事会组建的新的安全和安保委员会,该委员会负责对安全和安保决策提出建议。
OpenAI 在一篇博文中说:"OpenAI 最近已经开始训练其下一个前沿模型,我们预计这个新系统将使我们在通往 AGI(人工通用智能)的道路上达到更高的能力水平。”
虽然 GPT-5 可能需要几个月甚至更长的时间才能供用户使用(LLM 可能需要很长时间才能完成训练),但 OpenAI 下一代模型有哪些预期的功能,你知道吗?

更高的准确性
根据以往的发展趋势,我们可以预期 GPT-5 的回答将变得更加准确。因为它将在更多的数据上进行训练。像 ChatGPT 这样的生成式人工智能模型是通过使用它的训练数据库来提供答案的。
因此,模型接受的训练数据越多,模型生成连贯内容的能力就越强,性能也会更好。
迄今为止,每次发布的新模型,训练数据量都在增加。例如,有报道称 GPT-3.5 是基于 1750 亿个参数进行训练的,而 GPT-4 则是在一万亿个参数基础上训练的。
随着 GPT-5 的发布,我们可能会看到更大的数据跃升。
增强的多模态
在预测 GPT-5 的能力时,我们可以看看自 GPT-3.5 以来每个主要模型之间的差异,包括 GPT-4 和 GPT-4o。
每一次升级,模型都变得更加智能,并获得了许多改进,包括价格、速度、上下文长度和模式的变化。
GPT-3.5 只能处理文本的输入和输出。而使用 GPT-4 Turbo,用户可以输入文本和图像,并获得文本输出。
通过 GPT-4o,用户可以输入文本、音频、图像和视频的组合,并接收文本、音频和图像的任意组合输出。
按照这一趋势,GPT-5 的下一步将是具备输出视频的能力。今年 2 月,OpenAI 推出了文生视频模型 Sora,这该模型可能会被纳入 GPT-5 以实现视频输出功能。
自主行动能力(AGI)
不可否认,聊天机器人是非常强大的人工智能工具,能够帮助人们完成许多任务,例如生成代码、Excel 公式、论文、简历、应用程序、图表和表格等。
然而,我们发现,人们越来越希望人工智能能够知道你想要做什么,并且只需极少的指令就能完成,这就是 AGI(人工通用智能)。
有了 AGI,你可以要求AI助手完成一个最终目标,而AI助手则能够通过推理、计划和执行来实现这个目标。
例如,在 GPT-5 拥有 AGI 的理想情况下,你只需请求 "帮我订一份麦当劳汉堡 ",而人工智能就能完成一系列任务,包括打开麦当劳应用程序、下单、填写地址和付款。你所需要做的就只是等待享用汉堡。
AGI 作为人工智能的下一个前沿领域,可以彻底改变我们从人工智能获得帮助的方式,并改变我们对AI助手的看法。
我们将不再仅仅依赖人工智能助手来提供天气预报等简单信息,而是让它们自始至终帮助我们完成任务。





网友评论